It has been 100 days
最近每天都会头疼,可能是工作太忙了吧,今天回到家看了看监控系统的数据,发现新监控稳定运行100天了。
zabbix
现在的公司也有着几千台服务器,zabbix由于数据量太大,且后端的写数据只能写在mysql主上,系统一直不稳定,我曾和领导说过自己重复造轮子的想法,但是领导不是特别同意,自己一直也在犹豫,直到有一天zabbix出了一次大故障,丢了一部分数据,新的监控系统成为了我新一年的KPI,为了这套庞大的系统,我还挖来了前公司的同事A,其实是他自己的选择。哦,就在我写这篇文字的时候,zabbix又出问题了,其实大家都习惯了。
Zabbix history syncer processes more than 75% busy
the 1st commit
2016年9月29号,我写下第一行代码,开始设计整个系统核心模块(registry)的底层存储。
从一开始,我们就不断的在代码中加入测试,养成一个良好的习惯,并且在底层存储构建完成之后,接入到了CircleCI中。后来A接手了这个监控系统的核心模块,我开始负责agent、外部探测点、交换机流量采集、消息队列的开发和维护中,随着开发不断的推进,A还负责了报警模块的开发,其中包含了报警屏蔽、报警收敛等诸多功能。一路走来,我们踩了很多坑,加了无数的班,但是解决完问题的那种胜利感和成就感是无法用言语来形容的。一个内存泄漏就会使我们寝食难安,对代码高质量的要求,也让我们在后来的高并发场景中受益颇多:
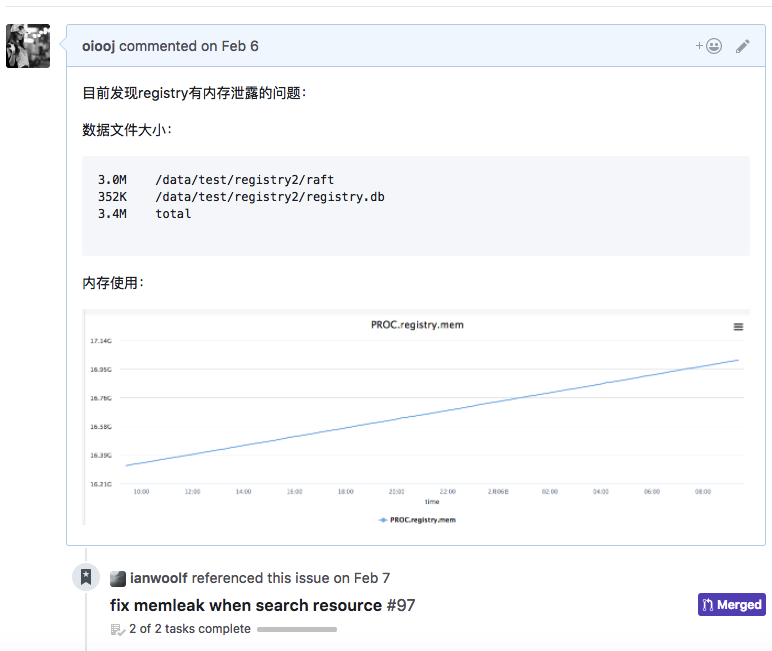
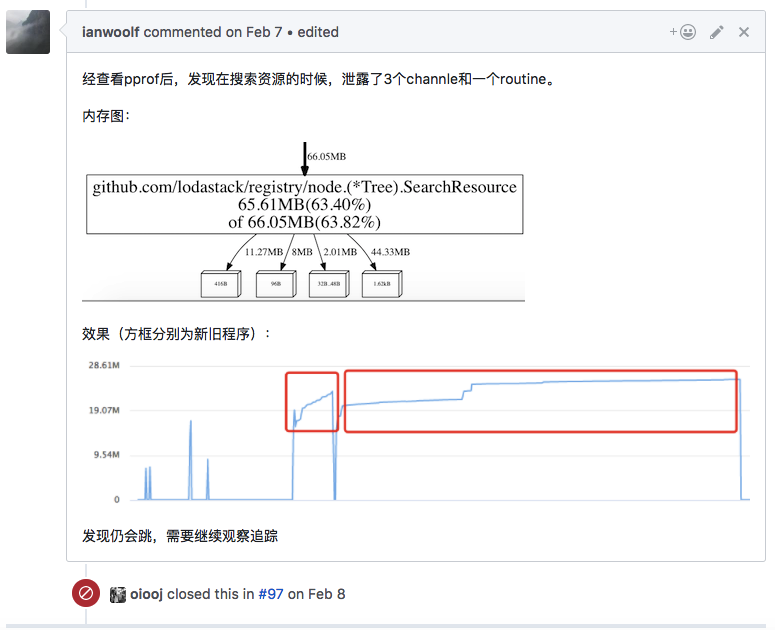
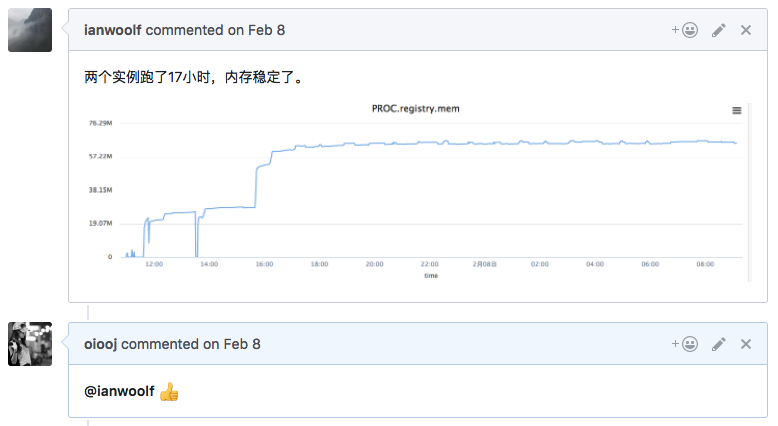
到现在为止 这个核心模块A写了15322行代码,我5602行代码。

Hightlight
- 这套系统配置数据和监控采集数据独立存储,重要的配置数据放在我们自己写的分布式存储中。
- 整套监控系统没有单点,没有状态,同步更新线上主机信息(主机名、IP)
- agent原生支持Windows/支持交换机采集
- 报警支持屏蔽和报警收敛
- 支持第三方打点上报,方便开发接入监控系统
- 得益于开源社区,拥有完善的插件库(一个redis可以上报60多项采集项,非常丰富)
- 图像展示速度优化,在长时间跨度查询的时候能够做到快速展示
- 在保证快速出图的同时,我们将一些关键的基础采集数据周期设置为10s(cpu.idle/mem.*)
- 支持grafana展示
- 基于服务树的严格灵活的权限管理和授权
- agent支持丰富的采集项,例如僵尸进程、网卡速度、网卡丢包、ntp时间误差等
- 由于底层的存储是自己写的,在模糊搜索某台机器的时候,可以在10ms内返回(排除网络)
- 服务器根据主机名自动注册到监控系统,根据节点的配置自动采集和报警
- 支持严格的接口可用性统计和计算(多点探测)
- 当某个机房的网络断掉时(公网异常),监控数据不会丢失,当某台机器完全断网不超过半个小,监控数据不会丢失
- agnet的安全性和性能是我们非常关注的问题,我们尽可能降低agent的资源消耗(mem.used<30MB cpu.used<1%),为此我们还砍了一些采集项目,为了安全,另外我们尽量减少agent直接执行命令的场景,领导的需求也被我们处于安全的考虑改用了其他方案。agent和server交互全部走https。
Status
到目前为止,服务树节点668,监控系统后端数据库每秒写入采集点 40000+, 每天有接近35亿的采集点被监控系统接收存储。registry的store存储层上次提交代码是在4个月前,内存消耗稳定在200多兆,CPU使用个位数,现在看来,还可以。