大数据量存储引起的Redis相关问题
1.问题
目前公司有个项目需要用Redis来存储一些数据,但是当开发导入数据的时候才知道,这个数据量是相当庞大的,接着就遇到了一些问题。 首先,Redis Master所在的物理机的内存是32GB,24核心的IBM X3530 M4。考虑到安全问题,当时做配置的时候我给Redis配置了20GB的内存,本来想着足够用了,但是后来当keys达到179658571条的时候,20G内存已经写满了,接着Redis就写不进去数据了.
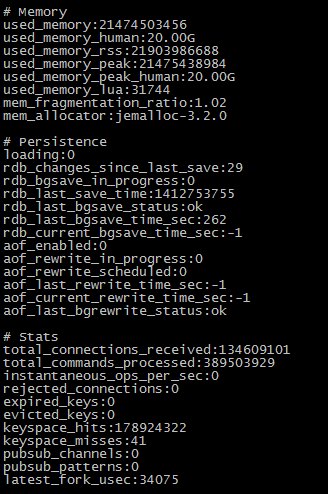

经同事提醒,想起Redis有个vm的配置,于是查阅资料,几个相关的参数如下:
是否使用虚拟内存,默认值为no
vm-enabled yes
虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享
vm-swap-file /tmp/redis.swap
将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的 (Redis的索引数据就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所value都存在于磁盘。默认值为0。
vm-max-memory 0
于是在配置文件中加上几条配置,但是报错了,居然还是语法错误:
Stopping ...
Waiting for Redis to shutdown ...
Redis stopped.
Starting Redis server...
*** FATAL CONFIG FILE ERROR ***
Reading the configuration file, at line 69
>>>'vm-enabled yes'
Bad directive or wrong number of arguments
后来发现,在新的Redis版本中vm相关的参数已经去掉了,线上server版本为 2.6.17。 无奈查看log,发现报错信息: [15964] 08 Oct 15:25:33.044 # Can’t save in background: fork: Cannot allocate memory
于是,从github上下回2.6.17的源码,开始查找问题出现在哪里。最终找到了上面报错的函数位于rdb.c中:
int rdbSaveBackground(char *filename) {
pid_t childpid;
long long start;
if (server.rdb_child_pid != -1) return REDIS_ERR;
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
start = ustime();
if ((childpid = fork()) == 0) {
int retval;
/* Child */
if (server.ipfd > 0) close(server.ipfd);
if (server.sofd > 0) close(server.sofd);
retval = rdbSave(filename);
if (retval == REDIS_OK) {
size_t private_dirty = zmalloc_get_private_dirty();
if (private_dirty) {
redisLog(REDIS_NOTICE,
"RDB: %zu MB of memory used by copy-on-write",
private_dirty/(1024*1024));
}
}
exitFromChild((retval == REDIS_OK) ? 0 : 1);
} else {
/* Parent */
server.stat_fork_time = ustime()-start;
if (childpid == -1) {
server.lastbgsave_status = REDIS_ERR;
redisLog(REDIS_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return REDIS_ERR;
}
redisLog(REDIS_NOTICE,"Background saving started by pid %d",childpid);
server.rdb_save_time_start = time(NULL);
server.rdb_child_pid = childpid;
updateDictResizePolicy();
return REDIS_OK;
}
return REDIS_OK; /* unreached */
}
发现是由于内存不足,父进程无法fork子进程回写数据照成的,这也证实了为什么后来重启Redis丢了2000W数据
同时查看了以前版本Redis的同名函数,代码如下:
int rdbSaveBackground(char *filename) {
pid_t childpid;
long long start;
if (server.bgsavechildpid != -1) return REDIS_ERR;
if (server.vm_enabled) waitEmptyIOJobsQueue();
server.dirty_before_bgsave = server.dirty;
start = ustime();
if ((childpid = fork()) == 0) {
/* Child */
if (server.vm_enabled) vmReopenSwapFile();
if (server.ipfd > 0) close(server.ipfd);
if (server.sofd > 0) close(server.sofd);
if (rdbSave(filename) == REDIS_OK) {
_exit(0);
} else {
_exit(1);
}
} else {
/* Parent */
server.stat_fork_time = ustime()-start;
if (childpid == -1) {
redisLog(REDIS_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return REDIS_ERR;
}
redisLog(REDIS_NOTICE,"Background saving started by pid %d",childpid);
server.bgsavechildpid = childpid;
updateDictResizePolicy();
return REDIS_OK;
}
return REDIS_OK; /* unreached */
}
很明显,新版本的该函数中已经去掉了 vm_enabled 参数。
2.总结
回到最本质问题,Redis只是对内存中的数据提出了一些持久化的解决方案,如果你要保存的数据特别大,比如上百G,在服务器内存一定的情况下,在大量key没有过期,无法淘汰掉的情况下,系统会考虑使用SWAP,(如果vm.overcommit_memory = 1 会直接放行),由于系统还有9G左右的剩余内存空间,所以并没有启用SWAP,于是Redis出现了一开始的问题。我想Redis去掉了vm特性,也是想把这部分的功能交给底层的系统来做吧。如果SWAP也不够用了呢,这时候估计不仅仅是Redis写不进去数据,就连系统也会出问题了吧。
我始终坚信:Cache就是Cache,我们不可能把所有数据放到内存中,那就尽量把热数据放到内存中吧,这不正是计算机为什么有了内存和磁盘吗,你说呢