Distributed service discovery system
Why
随着云服务和微服务的发展,在一个分布式系统中,服务之间的调用会变得越来越频繁、越来越复杂,而业务的运维变更也是非常频繁,再加上不可靠的硬件及软件服务,此时一个低成本、可靠、自动容错的服务调度显得尤为重要,减少对运维人的依赖,因此它对运维的服务质量、自动化都有着直接的影响。
而在传统的研发看来,配置文件依然是最常见的服务发现模式,这种方式导致服务之间在配置文件上深度耦合,当后端服务发生变化的时候,此时需要对调用端的配置文件进行相应的运维变更,成本高且易出错,显然是不合时宜。
Key Concepts
1、服务
是一个、组、类功能或者接口的业务描述,比如说注册用户、发送短信。转化到技术层面上就会对应一个api或者接口,此时会触发一次远程的RPC调用。
2、服务实例
服务实例是服务对应的一组IP和端口的简称。当前端服务需要请求后端某服务的时候,此时需要先找到对应的服务运行实例,也就是进程和端口,然后才能建立connection,从而发起请求。
3、服务注册
某个服务实例需要对外提供服务的时候,该服务实例应对外宣告自己能提供的服务有哪些,因此需要向服务中心进行注册,便于调用方能够发现这个服务。
4、服务发现
这是讲调用方通过某种方式找到被调用方,需要知道服务运行的位置(IP+PORT)。
5、服务调用
分为主调服务和被调服务,在一个合理的架构中,服务的调用应该是瀑布结构,即自上而下的顺序调用,而非环形调用,当然服务回调除外。
务调用的六种模式
这个地方并没有提出名字服务中心,因为有些方案实在不能称之为名字服务中心,更多是服务发现或者是一个简单的服务调用,但把它列出来,更多的是让大家去对比看一下,这些方案存在的问题,从而找到更优的方案。而对于一个分布式系统来说,服务是部署在多主机上,如何让调用者找到一个被调用者,我大体把它分为以下几种模式:
1、HardCode模式
有些研发直接把要访问的后端服务和端口写死在代码中,这种情况可以让该研发去面壁思过三天,不讨论了。
2、配置文件模式
这是最通行和最简单的模式,无论是后端web服务、还是mc、mysql等等,我们都可以配置在一个配置文件中(ini或者conf)等等。但后端服务发生变化了怎么办?此时运维要去做一次发布,增加了运维变更成本。如果故障了怎么办?会直接增加故障影响时长。配置文件是一种静态管理模式,需要对配置进行操作修改,带来的成本都是很大的。
3、类LVS模式
你一定见过很多内部服务都是走四层LVS模式,有些更可能走七层代理(nginx+keepalive):
A、引入一个组件是否就意味着架构变得复杂了?他的可靠性怎么保证?;
B、四层和七层代理模式所能探测的异常,是否和业务异常一致的?在四层情况下,四层正常不代表七层是正常的;在七层模式下,还有服务内部的异常情况,比如说服务器过载、socket句柄耗尽等等。
C、代理模式作为一个单点存在,特别对于包量和流量性服务来说,是否意味着是瓶颈;
4、DNS模式
太经典的模式。DNS是公网访问的常见模式,由于是标准协议,实现起来方便快捷。但依然是问题多多,
A、DNS服务发现模式粒度太粗,只能到IP级别,端口依然需要自己去管理;
B、对于后端一个异常服务来说,DNS无法提供自动容错的能力,此时便需要运维的参与,特别在设置了TTL(10S)的情况下;
C、DNS没法实现服务的状态收集,这部分信息反过来是可以为运维提供指导的;
D、DNS是一个静态的资源发现,DNS指向的变更都需要依赖工具来完成。
不过DNS还是有创新应用的地方,只是你我不知道。
5、总线bus模式
在以前很多SOA服务架构中,经常提到的是BUS总线架构,特别是在对历史遗留系统的整合中,也常提及这种模式,比如说以前的CORBA架构。看似服务透明且解耦,并且服务动态可扩展,但依然问题多多。
A、对总线的服务能力是个严峻的考验,海量的服务请求进入到总线,意味着中总线需要海量的处理能力;
B、总线还需要有QoS的服务能力,对不同的服务需要有不同的服务质量保证;
C、总线的高可用,如果很集中,则需要总线发布一致性保证,如果按照业务隔离总线,此时则对运维服务管理又是个负担,太多的总线和业务做了绑定和耦合。
在前不久和一个金融IT系统的人交流,他们早期采用的总线架构,后续逐渐下线掉,也都遇到了我说的几个问题。
6、类zk模式
自从google的chubby介绍一出,在不久之后便有了开源实现—zookeeper。chubby是基于paxos协议来实现的。为了实现zk的高可用,其集群必须是奇数个节点(3、5、7),一般是建议5个。奇数个节点有利于leade选举,偶数个节点是无法公平投票的。由于集群强一致性,当一个写请求递交到zk集群中,此时可以保证写入到所有节点中,那么对于读来说,读任何一个节点取得的结果是一致的。当然后面又有了etcd等等类似的服务。
基于服务树的服务发现
目前,机器装机完成会自动上报到服务树上,如果没有匹配到相应的节点,会自动注册到pool节点,对公司的机器管理形成一个闭环,减少人为遗漏,并且服务树很好的整理了服务节点关系,且每一个叶子节点都应该是一组独立的服务。而且服务树是一个分布式的服务,无论从可用性和性能方面都满足需求,况且每添加一个服务对整体系统的稳定性都是不利的。那我们就可以现有的利用服务树提供一个服务发现服务了。
用什么协议来实现确实是个难题,为了减少系统复杂度和业务侵入性,我们最终选择了DNS协议。这样做有几个好处:
- DNS协议是标准的,开发可以像使用一个正常的域名一样来使用服务,
- 服务树的节点名是一个NameSapce,在设计之初就是FQDN的格式,例如 db.monitor.loda 根节点是loda,我的服务集群是 monitor,这个域名会解析出我监控数据库的IP列表
- 前面也提到了DNS实现的缺点:我们打算在 NameSpace上携带一些要传递的信息,或则直接利用DNS的SRV记录
- 高性能的UDP协议
在接受延时的情况下,可以提供支持健康检查的DNS服务
[root@registry ~]# dig db.monitor.loda @127.0.0.1 ; <<>> DiG 9.9.4-RedHat-9.9.4-38.el7_3.1 <<>> db.monitor.loda @127.0.0.1 ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 29565 ;; flags: qr rd; QUERY: 1, ANSWER: 6, AUTHORITY: 0, ADDITIONAL: 0 ;; WARNING: recursion requested but not available ;; QUESTION SECTION: ;db.monitor.loda. IN A ;; ANSWER SECTION: db.monitor.loda. 60 IN A 10.91.0.7 db.monitor.loda. 60 IN A 10.81.0.150 db.monitor.loda. 60 IN A 10.81.1.150 db.monitor.loda. 60 IN A 10.91.150.8 db.monitor.loda. 60 IN A 10.81.21.149 db.monitor.loda. 60 IN A 10.91.21.206 ;; Query time: 0 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Sun Dec 24 14:14:59 CST 2017
我们将ttl设置成60s以便记录更新能快速被感知,为了提高解析性能,我们在内部实现上提供了一个cache来缓存解析结果。一个500条记录的结果在10ms左右返回,一个几十条的结果在1ms内能够返回。
架构
如果这个服务真正用在线上,无论是请求量和重要性都不言而喻,虽然服务树本身是一个可用性极高的服务(目前在4个IDC都有节点),但是服务树毕竟也是一个快速迭代、不断更新的服务,难免会有问题,总之一句话,鸡蛋不能放在一个篮子里,那么我们就在假设服务树整个集群全挂了的情况下,如何保证线上业务正常服务。
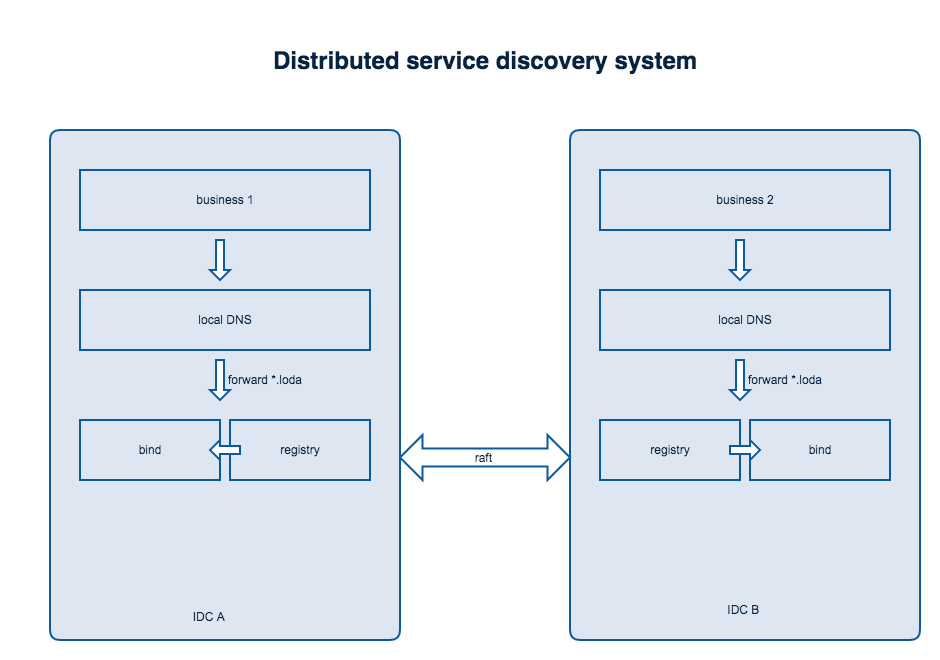
我们把*.loda的请求forward到服务树上来,服务树和bind共同维护一个VIP,如果服务树挂了,VIP将会被bind持有并提供服务,服务树和bind的关系为master-slave,为此我们专门提供了一个tool用来将服务的解析记录直接导出成bind的配置文件,方便定时同步数据到bind:
Sosara@MBA:~/golang/src/loda-cli$ ./loda-cli named
Sosara@MBA:~/golang/src/loda-cli$ more loda.zone
$TTL 60 ; 24 hours could have been written as 24h or 1D
$ORIGIN loda.
; line below expands to: localhost 1D IN SOA localhost root.localhost
@ 1D IN SOA @ hostmaster (
2017122414 ; serial
3H ; refresh
15 ; retry
1w ; expire
3h ; minimum
)
NS ns1
test.redis.bigdata.newsclient IN A 10.10.11.114
test.redis.bigdata.newsclient IN A 10.10.11.115
test.redis.bigdata.newsclient IN A 10.10.11.73
test.redis.bigdata.newsclient IN A 10.10.11.74
test.redis.bigdata.newsclient IN A 10.10.13.89
...
这样即使服务树挂掉,bind仍然能降级提供服务。