Bloom Filter
问题
我们常常遇到这样一个问题,检查一个数据有没有在一个数据集合中,比如 cache 的问题,我们可能经常使用一个 hash map 来解决这个问题,这样理论上的时间复杂度可以达到O(1),但是有些场景中我们要缓存的数据量非常非常大,全部放到内存中可能放不下,那么如何解决这个问题呢?
什么是 bloom filter
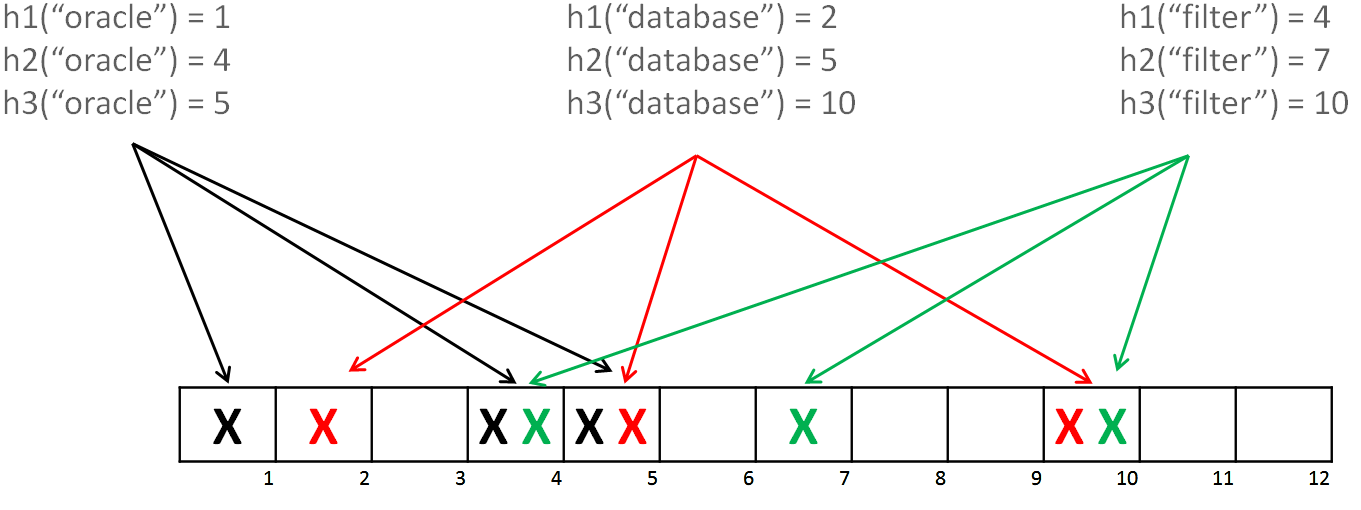
布隆过滤器是一个叫 “布隆” 的人在 1970 年提出的,它本身是一个很长的二进制向量,既然是二进制的向量,那么显而易见的,存放的不是 0,就是 1,这也是底层布隆过滤器为什么能够节省空间的原因之一。布隆过滤器使用多个 hash 算法将要查询的值映射到二进制向量中,如果原来值为 0 则更新为 1。
Hash1(数据)=1
Hash2(数据)=4
Hash3(数据)=5
这样,我们就把第 1、5、7 个元素的 bit 值设置为 1。下次查询的时候,如果第 1、5、7 个元素的值都为 1,说明这个值很可能已经在这个集合中了,为什么说是 ”有可能“ 呢,因为 hash 是有碰撞的可能的,随着添加的值不断增加,碰撞的可能也越来越大。
但是如果 1、5、7 中如果有一个不为 1 ,我们可以非常肯定的说这个数据没有被添加到这个集合中。
优缺点
优点:由于存放的不是完整的数据,所以占用的内存很少,而且新增,查询速度够非常快
缺点:随着数据的增加,误判率随之增加,无法做到删除数据,只能判断数据是否一定不存在,而无法判断数据是否一定存在。
使用场景
- cache 查询
- 大量 tags/labels 查询
总之,判断一个数据有没有在一个大量的集合中的问题,基本都可以使用 bloom filter 来解决,误判率的问题在一定场景下也是可以解决的。